Java服务监控分析及案例 - CPU篇
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而每一次的上下文切换过程都会给系统带来一定的资源和时间的开销,这也是我们需要关注上下文切换的原因。
在Linux中,按照特权等级会将进程运行空间分为用户态和内核态,而只有内核态可以访问所有资源(包括内存,寄存器等硬件设备)。
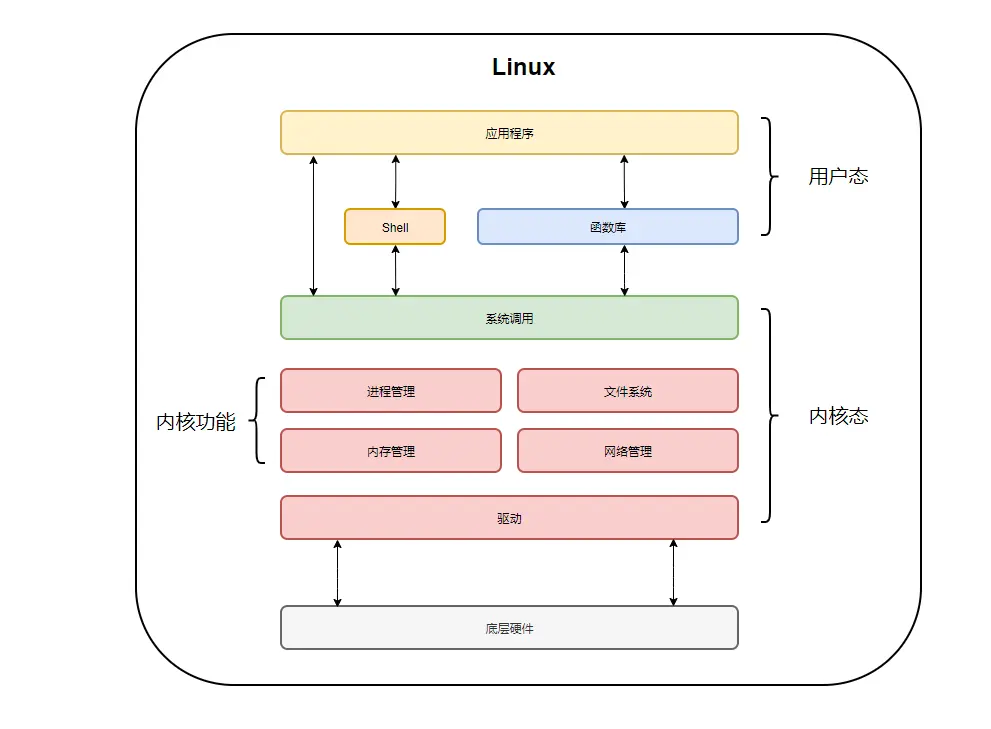
当切换上下文时,应用需要从用户态陷入到内核态去访问寄存器和程序计数器,从而保存当前上下文并读取接下来执行程序的上下文,这个过程会带来一定的资源消耗。
上下文切换类型
对于上下文切换,根据任务的不同分为如下几种类型:
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
| 类型 | 是否切换地址空间 | 是否清空/恢复CPU缓存 | 是否切换栈和寄存器 | 开销级别 |
|---|---|---|---|---|
| 进程上下文切换 | 是 | 是 | 是 | 最大 |
| 线程上下文切换 | 否 | 否 | 是 | 中等 |
| 中断上下文切换 | 否 | 否 | 部分寄存器 | 最小 |
(同一进程中的)线程上下文切换会比进程上下文切换的开销和耗时更小,这也是多线程替代多进程的优势。
如何查看上下文切换情况
- vmstat

通过vmstat查看系统整体的上下文切换情况,对于上下文切换,我们可以只关注图中标注的参数:
procs.r: 就绪队列的长度,其中存在的是Runnable状态的进程,等待CPU分配时间片运行。
procs.b: 不可中断状态的进程数
system.in: 每秒中断次数
system.cs: 每秒上下文切换次数
- pidstat
查看进程上下文切换的情况
1 | # 每隔5秒输出1组数据 |
查看线程上下文切换的情况
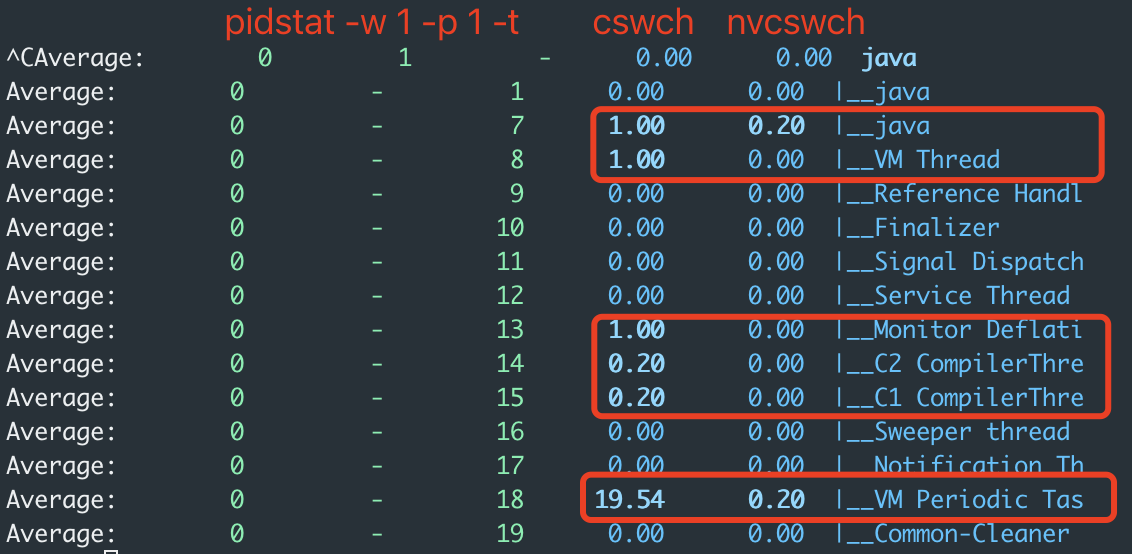
1 | $ pidstat -w 1 -p 1 -t |
cswch 表示每秒自愿上下文切换(voluntary context switches)的次数。
- 对于进程而言,指的是自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。 I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 对于线程而言,指的是自发性上下文切换,具体含义会在后续章节中介绍。
nvcswch 表示每秒非自愿上下文切换(non voluntary context switches)的次数。
- 对于进程而言,指的是非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。 大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
- 对于线程而言,指的是非自发性上下文切换,具体含义会在后续章节中介绍。
注: 为了区分进程和线程的上下文切换,对于线程而言,命名为自发性/非自发性上下文切换,但实际上含义与自愿/非自愿上下文切换相同。
Java应用中哪些操作会触发上下文切换
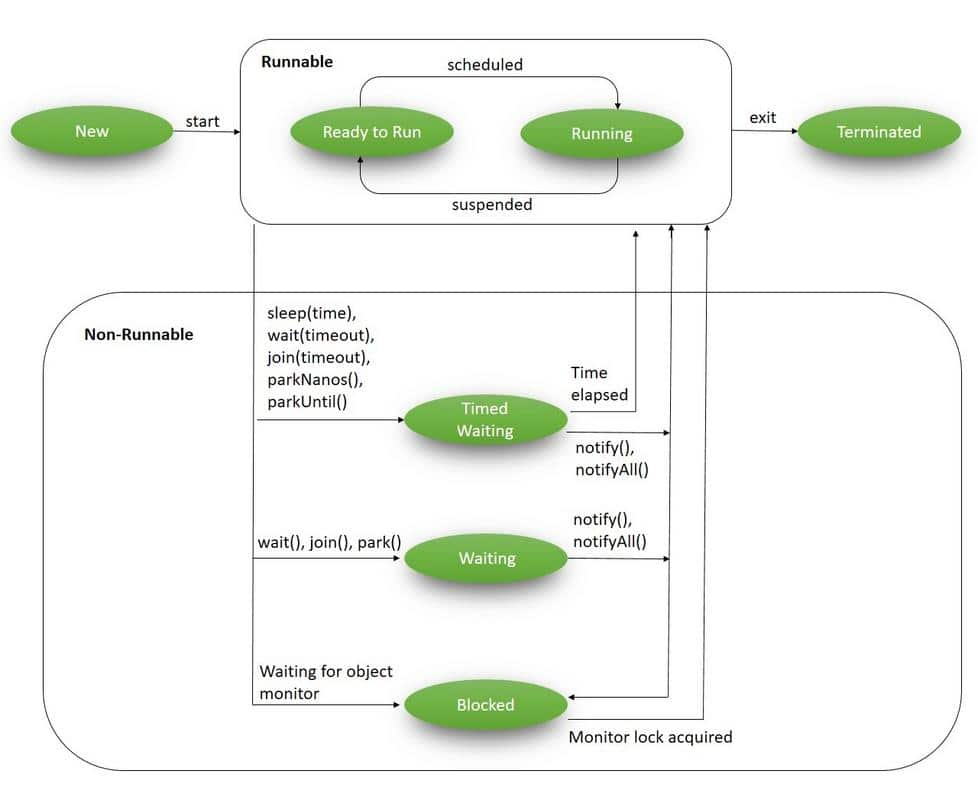
在Java应用中,线程上下文切换是由于线程从RUNNABLE状态转为Non-Runnable状态,或是从Non-Runnable状态转为Runnable状态触发的。
而导致状态切换的操作分为两种:自发性上下文切换和非自发性上下文切换。
自发性上下文切换就是由于上图中的方法调用导致的,例如:sleep, wait, join, notify等,当然也包括锁的获取和释放,例如: lock和synchronized
而非自发性上下文切换则是由于调度器的原因而被迫切出,例如:被分配的时间片用完,垃圾回收相关的stop-the-world事件。
多线程一定比单线程执行快吗?
多线程被视为提高程序性能的一种手段。通过并行处理,多线程可以充分利用多核处理器的能力,从而提高程序的响应速度和吞吐量。
然而,这并不意味着在所有情况下多线程都能比单线程快。我们可以通过一个简单的Java代码案例来分析这一现象。
案例
对于单线程/多线程实现案例,都使用相同的resource quota配置:
1 | resources: |
单线程实现:
1 | public class SingleThreadExample { |
多线程实现
1 | public class MultipleThreadExample { |
通过将代码部署到本地colima Kubernetes集群中进行测试。这里代码中加入while(true)循环是为了防止单次执行完毕后Pod直接转为Complete状态 (Complete状态无法采集一定时间的上下文切换数据)。
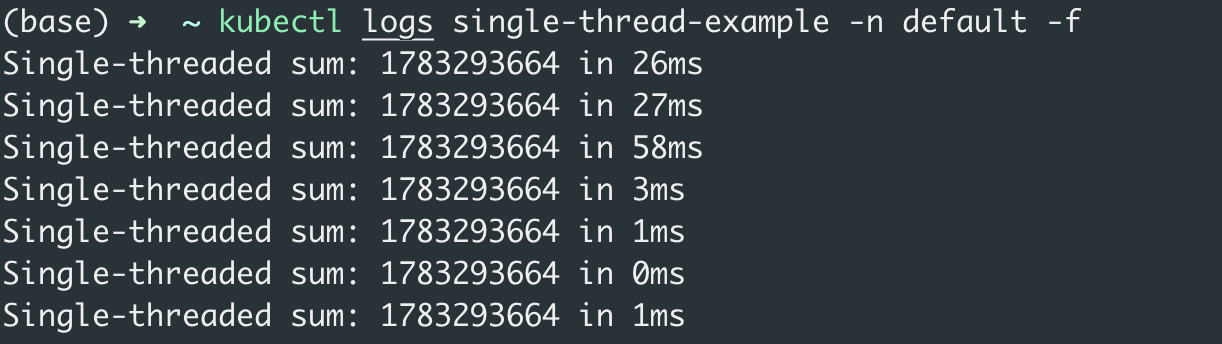
单线程实现:
多线程实现:
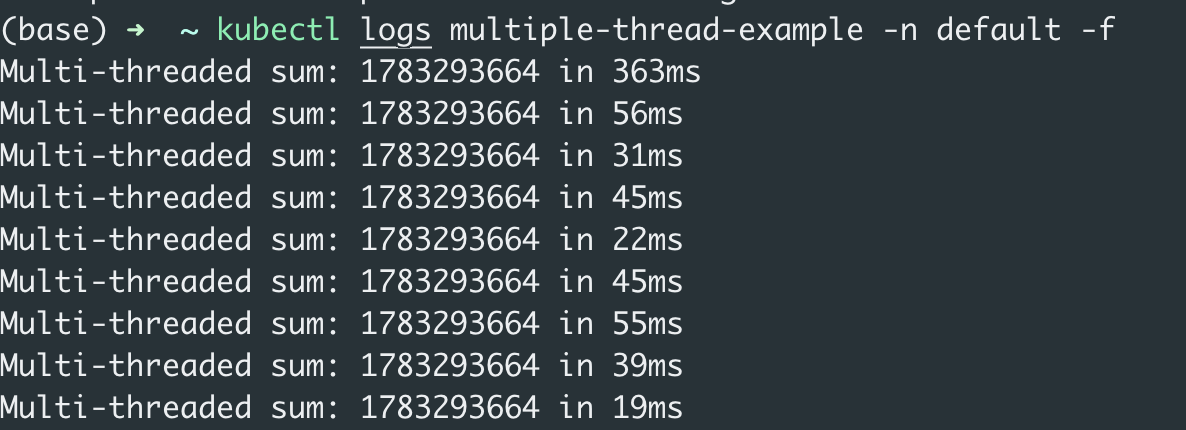
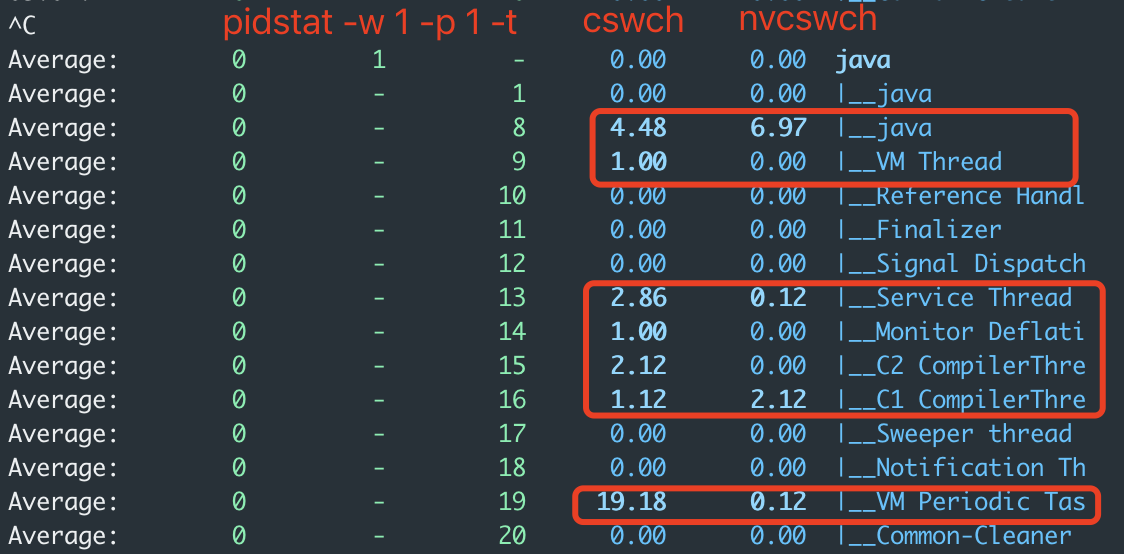
从上述截图可以明显看到多线程实现的耗时比单线程更长,多线程实现的上下文切换次数比单线程实现的更多。并且多线程实现在刚启动时耗时比单线程实现高出10倍以上,这是因为创建线程池和线程都会带来额外的开销。
所以说并不是所有情况下多线程实现都比单线程快,尤其是这种计算密集型的任务。
这就如同下图所示,工作人员同时处理多个任务时反而会陷入焦头烂额的状态,远不如一个一个任务执行时候来的轻松,效率高。

多少的上下文切换次数合理
这个数值其实取决于系统本身的 CPU 性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
合理设置线程池大小
日常工作中,常常会思考到底将线程池大小设置多大比较合理,如果将线程数设置过大,线程会频繁的争用有限的CPU时间片,导致更多的非自发性上下文切换。但如果线程数设置过小,则无法充分利用计算机资源。
实际上,设置线程池大小需要根据任务的类型来合理分配,而任务类型通常分为:
- CPU密集型
- I/O密集型
CPU密集型
CPU密集型型的任务主要的瓶颈在于计算能力,设置过多的线程并不会提升CPU的计算能力,反而增加了创建线程,销毁线程以及上下文切换的开销。
下面就通过一个案例说明如何配置线程池大小能够让应用处理CPU密集型任务更快。
案例
此处我们可以复用多线程一定比单线程执行快吗?的案例进行说明。
对于多线程实现的耗时计算,我除去了第一次构建线程池的长耗时进行平均值计算。
| 场景 | 平均耗时(ms) | 平均cswch | 平均nvcswch |
|---|---|---|---|
| 单线程 | 28.5 | 1 | 0.2 |
| 线程池 (n=2) | 38.5 | 4.48 | 6.97 |
| 线程池 (n=3) | 54.75 | 6.53 | 4.98 |
| 线程池 (n=4) | 63.25 | 7.87 | 6.27 |
| 线程池 (n=5) | 73.25 | 8.68 | 9.48 |
根据表格所示的结果,对于CPU密集型的任务,增加线程数来并行处理任务并没有带来性能提升,反而会因为过多的上下文切换以及线程调度的开销导致耗时变长。
所以对于CPU密集型任务,如果想要性能最大化,我们要做的是增加CPU核心数并且设置和CPU核心数相等的线程数来处理任务。
I/O密集型
I/O密集型任务的主要时间花费在等待外部设备或者服务的响应,而在等在响应的这段时间内线程处于空闲状态,这个时候设置更多的线程数反而能带来性能提升的效果,
尽管线程切换(上下文切换)有一定的开销,但在I/O密集型任务中,这种开销相较于I/O操作的时间消耗是非常小的,可以忽略不计。因此,我们可以通过增加线程数来充分利用CPU和资源,而不会因为上下文切换显著降低性能。
下面就通过一个案例说明如何配置线程池大小能够让应用处理I/O密集型任务更快。
案例
1 | public class IOIntensiveExample { |
同样将上述Java代码部署到本地colima Kubernetes集群中进行监控和测试。
| 场景 | 平均耗时(ms) | 平均cswch | 平均nvcswch |
|---|---|---|---|
| 单线程 | 290.5 | 5.26 | 3.19 |
| 线程池 (n=2) | 218 | 4.49 | 20.54 |
| 线程池 (n=3) | 300.5 | 5.68 | 23.31 |
| 线程池 (n=4) | 321.5 | 8.15 | 15.92 |
| 线程池 (n=5) | 364.5 | 9.24 | 17.75 |
根据以上表格所示,对于I/O密集型的任务,通常将线程数设置为CPU核心数的2倍可以得到更好的性能。