JPA batch insert和batch delete的重构和性能优化
背景
在项目中,我们作为kafka message消费处理并转发的平台服务,被external consumer“吐槽”消费处理并转发的速度太慢了,从开始consume到全部publish out的整个流程需要7个小时。
External consumer要求我们需要在2小时内将所有相关消息处理并publish out。
本文主要讲解如何不改动insert代码逻辑,只需修改配置,即可完成batch insert性能优化。对于batch delete的重构只会给出解决方案。
下面先给出优化前后处理单条数据流的结果对比图:
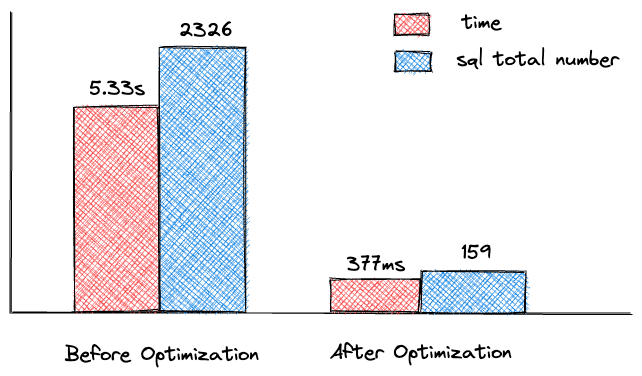
1. 排查原因
1.1 调查报告
经过排查,我们发现主要耗时在数据持久化的环节,下图是单条数据流的处理结果。
| Sql | Span | Time |
|---|---|---|
| insert into order_item (xxx,xxx) values (?) | 498 | 1.12s |
| insert into order_item_location (xxx,xxx) values (?) | 498 | 1.05s |
| insert into order_item_location_stock (xxx,xxx) values (?) | 168 | 711ms |
| delete from order_item where order_item_id = ? | 498 | 1.06s |
| delete from order_item_location where order_item_location_id = ? | 498 | 1.05s |
| delete from order_item_location_stock where order_item_location_stock_id = ? | 166 | 350ms |
根据上述表格,可以看出insert, delete sql执行多次,耗时长达5~6s
因此我们需要分别对服务中的insert, delete操作进行重构和性能优化,以此减少insert, delete sql执行的次数,从而降低耗时,提升性能。
1.2 Entity relationship code example
给出代码示例如下:
1 |
|
2. batch insert性能优化
首先对insert操作进行优化,由于我们之前使用的是JPA cascade生成的级联insert sql,这里cascade insert会对关联表one by one insert,所以会导致生成非常多的insert语句。
1 | public void saveOrder(Order order) { |
通过调研发现JPA和Postgresql提供一些batch insert配置,接下来将详细介绍如何通过只增加配置对insert操作进行性能优化,而无需重构code base中的insert代码。
2.1 Postgresql reWriteBatchedInsert config
首先介绍的是Postgresql JDBC Driver支持的reWriteBatchedInsert配置。
2.1.1 简单代码示例
1 |
|
1 | spring.jpa.properties.hibernate.jdbc.batch_size = 10 |
1 | // 循环insert 5个Book Entity into database |
在未激活reWriteBatchedInsert配置时,执行sql如下所示:
1 | LOG: execute S_2: insert into book (title, id) values ($1, $2) |
当我们激活PostgreSQL的reWriteBatchedInsert配置后,激活配置如下:
1 | spring: |
现在再次执行循环insert操作,执行sql如下所示:
1 | LOG: execute <unnamed>: insert into book (title, id) values ($1, $2),($3, $4),($5, $6),($7, $8),($9, $10) |
可以看到当激活reWriteBatchedInsert配置后,原来执行5条insert sql,现在只需要执行1条。
2.2 JPA batch size和order_insert config
JPA中当设置了batch size为合理的数值并激活reWriteBatchedInsert配置,即可达到batch inset的效果。
但是当此时有多个table需要进行insert操作时,且insert语句不按照table顺序依次执行,则会导致batch insert失效。
举例说明,我们有两个不同的entity: entityA和entityB
1 | entityARepository.save(entityA1); |
设置order_inserts = false
JPA会执行如下的sql语句:
1 | insert into A - (A1) |
可以看到,当order_inserts为false时,即使我们激活了reWriteBatchedInsert配置,并且设置了batch_size大小为30,但batch_insert却没有生效。
设置order_inserts = true
JPA会执行如下的sql语句:
1 | insert into A - (A1, A2) |
可以看到当设置order_inserts = true时,JPA会进行reorder inserts,并基于此进行batch insert操作。
2.3 Batch inserts失效 (For Identity identifier generator)
但当我们使用Identity identifier generator (即使用注解@GeneratedValue(strategy = GenerationType.IDENTITY)) 来生成主键时,bacth inserts也会失效。
Hibernate的官方文档有如下说明:
Hibernate disables insert batching at the JDBC level transparently if you use an identity identifier generator.
为什么会有这样的限制呢?Hibernate官方文档也给出了一定的解释:
It is important to realize that using IDENTITY columns imposes a runtime behavior where the entity row must be physically inserted prior to the identifier value being known.
This can mess up extended persistence contexts (long conversations). Because of the runtime imposition/inconsistency, Hibernate suggests other forms of identifier value generation be used (e.g. SEQUENCE) with extended contexts.
简单来说,就是使用Identity identifier generator会强加一种运行时行为,导致无法在insert语句执行之前知道identifier generator生成的值。
这样的行为会打乱persistence context,所以Hibernate建议我们使用其他类型的identifier generator。
2.4 Sequence identifier generator
基于如上原因,我们需要修改identifier generator为Sequence。
Sequence identifier generator可以在insert语句执行之前生成自增id的值,这对于PostgreSQL这种可以访问native sequence的数据库而言非常适用。
1 |
|
1 | CREATE SEQUENCE public.order_item_id_seq INCREMENT 1 START 1 MINVALUE 1; |
当使用JPA提供的sequence identifier generator时,我们需要在数据库中创建与annotation中名称一致的native sequence。
否则会出现以下的异常信息:
1 | org.postgresql.util.PSQLException: ERROR: relation "public.order_item_id_seq" does not exist |
但是测试时,又发现了一个新的问题,因为sequence identifier generator会在每次insert语句执行之前查询需要生成的主键的值。
1 | SELECT nextval('public.order_item_id_seq'); -- Returns 1 |
在有很多的记录需要insert时,会产生大量的select nextval语句,对整体的处理时间产生影响(处理时间变长)。
2.4.1 Sequence generator allocationSize
解决方案:将@SequenceGenerator中的allocationSize设置为10
1 |
|
同时还需要修改数据库的sequence的increment值,使其与allocationSize保持一致。
1 | ALTER SEQUENCE public.order_item_id_seq INCREMENT 10; |
这里的allocationSize意味着每次会从数据库中获取10个值,以用作主键生成,这样就可以避免每次insert都需要查询sequence的nextval了。
但为什么会选择allocationSize为10,而不是更大的值呢?
举个例子,假设我们将allocationSize设置为50,当程序运行中突然重启,我们会看到如下结果:
1 | INSERT INTO order_item (order_item_id) VALUES (1); |
可以看到重启之后,新的主键值从52开始了,主键值之间出现了较大的gap,这是我们不希望看到的,所以我们将allocationSize的值设置为10。
但这也是JPA/Hibernate sequence strategy的一种权衡,可以将其理解为一种“线程安全”的行为。当多个应用访问数据库时,每个应用都会持有自己的identifier block,所以可以避免主键冲突的情况发生。
2.5 hibernate.id.optimizer.pooled.preferred
那么Hibernate是如何保证sequence identifier generator在并发情况下是“线程安全”的呢?
依靠的就是hibernate.id.optimizer.pooled.preferred参数,这个参数是Hibernate提供的对于identifier generate strategy的一个优化器配置。
该配置支持四种不同的optimizer,分别是none, hilo, pooled, pooled-lo,由于篇幅有限,感兴趣的小伙伴可以自行查阅这四种optimizer的不同。
在使用sequence identifier generator并配置了allocationSize > 1时,Hibernate会默认使用pooled optimizer,
2.5.1 pooled-lo optimizer
这里为了更易于解释,我们采用了pooled-lo optimizer,它的工作流程如下:
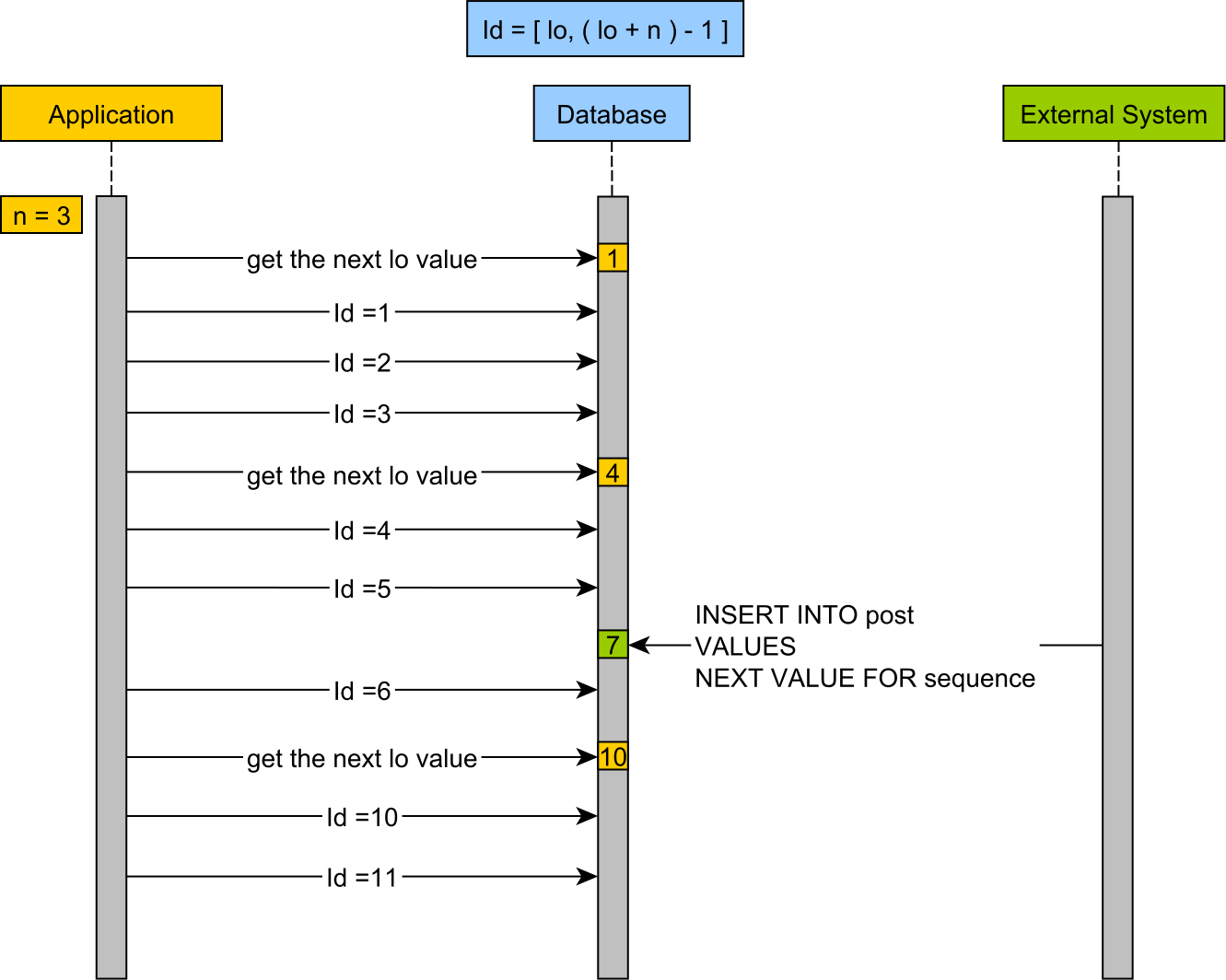
从图中可以看到,id block的区间 (即应用从database获取的id block的区间) 是 [lo, (lo + n) - 1],第一次获取lo的值为1,则id block为 [1, 3],第二次的id block为 [4, 6],以此类推。
但同一时间有外部系统也要insert时,数据库中sequence从1~6的值已被Application占用,所以此外部系统获取到的lo值为7,其对应的id block为 [7, 9]。
那么图中Application的最后一次获取的lo值为10,id block为 [10,12]。
这样就保证了在并发情况下,JPA/Hibernate可以高效且不会发生主键冲突的完成identifier generate工作了。
3. batch delete重构
相对于batch insert的优化来说,batch delete会简单很多。
3.1 代码示例
Entity relationship在 1.2章节 中查看,目前Entity的delete操作是通过JPA OneToMany Cascade Delete完成的。
1 | public void deleteOrder(Order order) { |
但在数据量较大的情况下,Cascade Delete会生成大量的delete语句,这是因为Cascade Delete是delete one by one而不是delete in batch。
3.2 重构方案
所以如果你的服务对性能或要求比较高,且需要Cascade Delete数据较多时,那么使用OneToMany Cascade Delete就不是一个合适的方案了。
废话不多说,直接上解决方案:
- 修改OneToMany的CascadeType为
@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE, CascadeType.REFRESH}, fetch = FetchType.EAGER)。 - 修改deleteOrder方法:
- 根据OrderId查询需要删除的OrderItemId,OrderItemLocationId,OrderItemLocationStockId。
- 接着使用deleteAllByIdInBatch方法分别删除OrderItemLocationStock,OrderItemLocation,OrderItem,最后再删除Order。
重构之后,当调用deleteOrder方法时,即会看到如下的sql:
1 | delete from order_item_location_stock where order_item_location_stock_id in (?) |
重构后,delete语句的数量明显减少了,由原来的近1000条delete语句,变成了只有4条delete语句执行。
4. 优化前后结果对比
经过了对insert,delete的重构和性能优化,最终单条数据流的处理结果如下:
| Sql | Span | Time |
|---|---|---|
| select nextval (?) | 116 | 181ms |
| insert into order_item (xxx,xxx) values (?) | 17 | 49.5ms |
| insert into order_item_location (xxx,xxx) values (?) | 17 | 43.8ms |
| insert into order_item_location_stock (xxx,xxx) values (?) | 6 | 17.9ms |
| delete from order_item where order_item_id in (?) | 1 | 6.49ms |
| delete from order_item_location where order_item_location_id in (?) | 1 | 8.59ms |
| delete from order_item_location_stock where order_item_location_stock_id in (?) | 1 | 4.70ms |
总耗时 377ms。
经过优化后,目前从开始consume到publish out的整个流程只需要40分钟,相比于优化前需要7个小时完成,有了一个很大的提升。